Data Collection
Overview
For this project we have collected data pertaining to installable libraries/packages for programming languages like Python, Julia and R. In addition to that, we have collected project-level repository information for Code.gov
Modern programming languages like Python, Julia and R, have built-in package registries like PyPi, JuliaPackages, CRAN, etc. Therefore, the data collection task involves accessing the registry as a file or through REST endpoints or by using web-scraping techniques to get a list of packages. Most of these registries also contain metadata for the packages like
- Author name
- License
- Source code URL
- Version history
- Downloads
- Date of creation, etc
Once we relate a package to its source code URL, it’s relatively easy to obtain the repository-level and commit-level information for the project. The data collection for the packages can be broken down into the following steps:
- Obtain the list of packages
- Obtain metadata for the packages along with their GitHub URL
- Get repository-level information for the packages through their respective GitHub URL
- Get commits-level information for the packages through their respective GitHub URL
Data collection from PyPi for Python
The first step in the data collection task for Python is to get a list of all the packages. This was accomplished by making RPC request to https://pypi.python.org/pypi using a built-in Python package called xmlrpc
At the time of our research, we obtained 441095 packages from the RPC endpoint
The next step is to get the metadata for each package now that we have package names. To do that, we made REST requests to package-specific endpoints which looks something like this https://pypi.org/pypi/{package_name}/json
When you make request to a package, for example requests, you get the following JSON which contains the metadata
{
"info": {
"author": "Kenneth Reitz",
"author_email": "me@kennethreitz.org",
"bugtrack_url": null,
"classifiers": [
"Development Status :: 5 - Production/Stable",
"Environment :: Web Environment",
"Intended Audience :: Developers",
"License :: OSI Approved :: Apache Software License",
"Natural Language :: English",
"Operating System :: OS Independent",
"Programming Language :: Python",
........
],
"description": "# Requests\n\n**Requests** is a simple, ...n",
},
"home_page": "https://requests.readthedocs.io",
"keywords": "",
"license": "Apache 2.0",
"maintainer": "",
"maintainer_email": "",
"name": "requests",
"package_url": "https://pypi.org/project/requests/",
"platform": null,
"project_url": "https://pypi.org/project/requests/",
"project_urls": {
"Documentation": "https://requests.readthedocs.io",
"Homepage": "https://requests.readthedocs.io",
"Source": "https://github.com/psf/requests"
}
..........
..........
..........
..........
}The metadata thus obtained has a lot of relevant information about the package like 1. Package versions 2. Package dependencies 3. Package URLs (source code, homepage) 4. Package creation date 5. Package description summary 6. Package authors, etc
This step is followed by flattening the JSON objects to obtain a table
Data collection from CRAN for R
The data collection process for R is relatively straightforward, thanks to their logs’ database that can be accessed through a user-friendly API. The logs’ database can be accessed through a library called cranlogs for R which provides wrapper functions for the database calls. We collected the following information for each package in CRAN. 1. Package 2. Version 3. Dependencies 4. License 5. Author 6. Description 7. Maintainer 8. Title 9. Source URL 10. Reverse Dependencies
This package can also be used to obtain daily downloads count for each package in CRAN. We obtained the “overall downloads” by summing over the daily downloads, and we obtained the “yearly downloads” by aggregating the download counts yearly.
The results were joined to form the main table.
Data collection from JuliaPackages for Julia
The Julia package registry resides on GitHub at https://github.com/JuliaRegistries/General. In this repository, we can find a file named Registry.toml. This file contains an exhaustive list of all the packages in the JuliaPackages registry in .toml format which is similar to .ini format for storing configuration files. Once we obtain the list of packages, we obtained the relevant source code URL for the packages using a Julia package called PackageAnalyzer. This package contains functions to obtain the GitHub URL associated with the package names. Now we have a dataframe that has the following columns,
- Package Name
- GitHub URL
The source code for the Julia packages must be structured to contain the following files and folders
./src
./test
README.md
LICENSE
Manifest.toml
Project.tomlThe file pertinent to our task is Project.toml which contains metadata like 1. Authors 2. Dependencies 3. Version
Accessing the Project.toml file for all the packages seems like a hard task as they are scattered across different GitHub repositories. But we already have the GitHub repositories associated with the packages. Therefore, now the task of accessing the Project.toml file boils down to making HTTP GET requests to https://raw.githubusercontent.com/{user}/{repo_name}/master/Project.toml for each user and repo_name in the GitHub URLs we collected.
This was followed by joining the dataframes and flattening out the metadata.
Using GitHub GraphQL API to collect more metadata
As we have discussed before, for Python, Julia and R packages, we have collected their respective source GitHub URLs. This can give us a lot of information at both repository and commits level.
The repository-level data for the packages aid in getting more metadata like- 1. Created date 2. Description of the project 3. Readme 4. Fork count 5. Stargazer count 6. Issues count, etc
The commits-level data lets us have a more granular look into the package development. We can obtain the number of lines of codes added and deleted by each developer for the package which aids us in determining the key developers for the package. We can also get a time-series view of the package development.
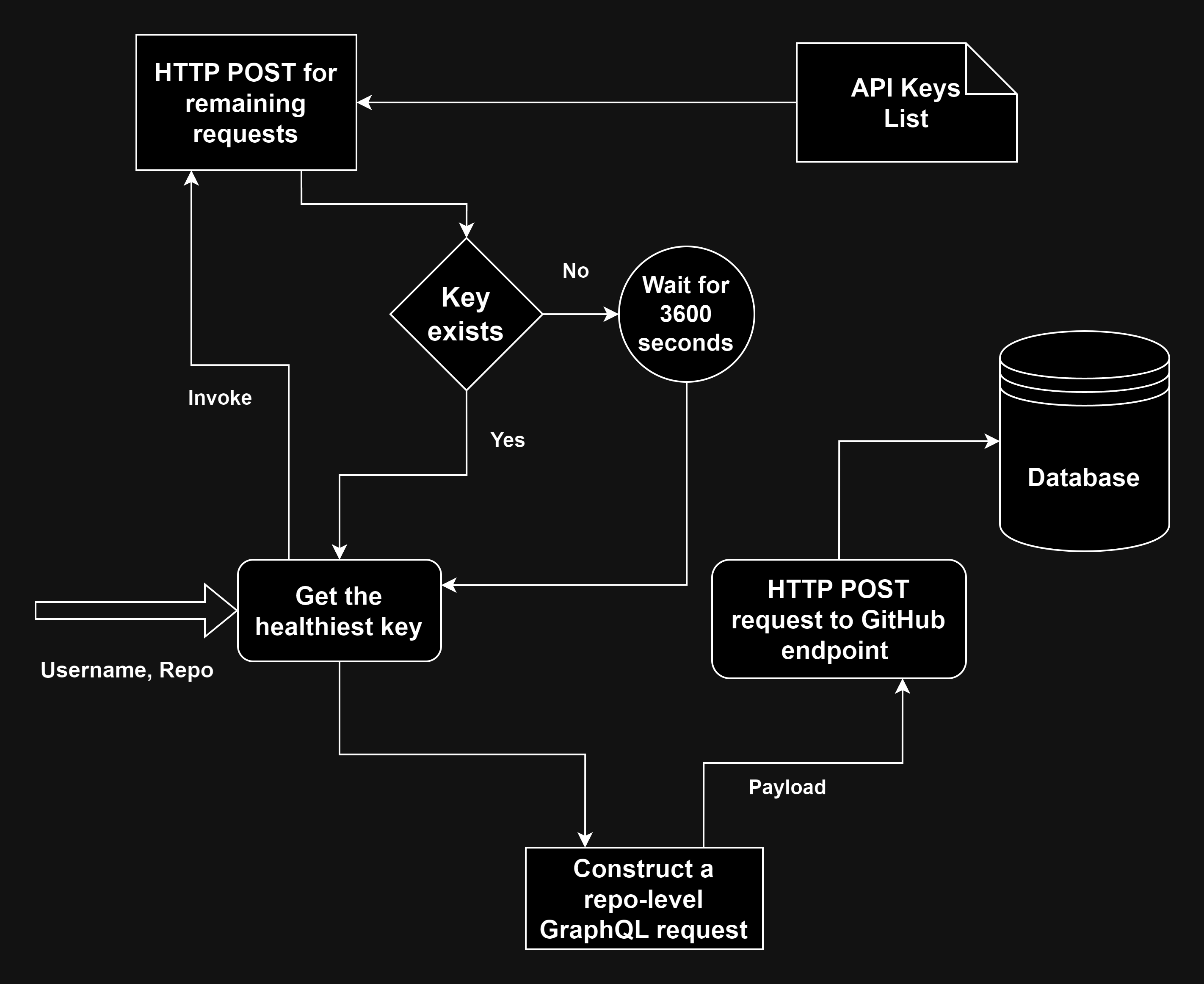
Collection of GitHub repository-level information for the packages
One of the main problems with collecting huge amounts of data from the GitHub API is rate-limits. At the time of writing, the rate-limit associated with the GitHub GraphQL API is 5000 requests per hour. To handle this issue, we use a list of multiple GitHub API keys to collect data. For every query, we use the least-used key, thereby going through all the keys.
The GraphQL query to check the health of an API key is of the following form
query {
viewer {
login
}
rateLimit {
limit
cost
remaining
resetAt
}
}In addition to this, we also had to handle secondary rate limits which prevent a client from making “too many” requests in short durations. This can be circumvented by adding a random delay between 0.5 to 3 seconds before every request.
query {
repository(owner: "%s", name: "%s") {
name
description
shortDescriptionHTML
url
createdAt
updatedAt
pushedAt
forkCount
stargazerCount: stargazers {
totalCount
}
issues(states: OPEN) {
totalCount
}
pullRequests(states: OPEN) {
totalCount
}
owner {
login
}
licenseInfo {
name
spdxId
url
}
object(expression: "HEAD:README.md") {
... on Blob {
text
}
}
}
viewer {
login
}
rateLimit {
limit
cost
remaining
resetAt
}
}The data collection mechanism to collect the repositories is represented in the block diagram below.
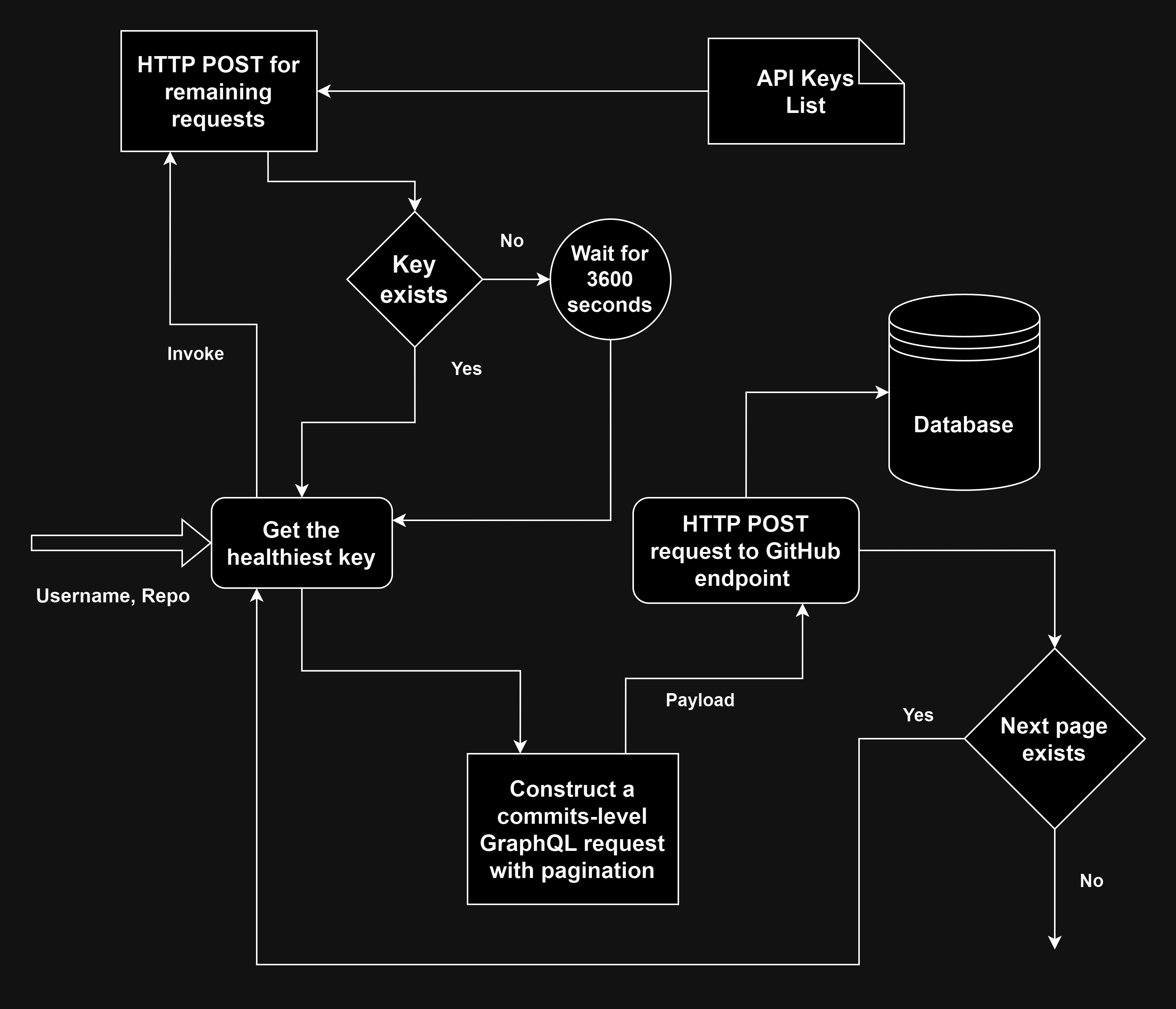
Collection of GitHub commits-level information for the packages
Along with the challenges associated with primary and secondary rate-limits that we discussed previously, we also run into problem with query limits with collecting commits data.
In the case of the repository-level query, we essentially have one row of data in the response. But querying commits for a repository will have as many rows as the number of commits for the repository. If the result of the query turns out to be more than 1000 (query limit at the time of writing) rows, the GraphQL query only returns the first 1000 rows and truncates the remaining results.
To solve this problem, we can use pagination. Pagination helps divide the query into multiple chunks of 1000 called ‘pages’. This means that we need to run the query multiple times for the same repository till there aren’t any more pages.
The GraphQL query used for this task is of the following form
query ($cursor: String) {
repository(owner: "%s", name: "%s") {
defaultBranchRef {
target {
... on Commit {
history(first: 100, after: $cursor, since: "%s") {
pageInfo {
hasNextPage
endCursor
}
edges {
node {
oid
messageHeadline
author {
name
email
date
user {
login
location
company
pronouns
bio
websiteUrl
twitterUsername
}
}
additions
deletions
}
}
}
}
}
}
}
}The data collection mechanism to collect the commits-information is represented in the block diagram below.